NLP matching is only as good as its inputs. When a learning team plans to recommend external courses against an internal capability taxonomy, the text on both sides has to be rich enough that a matcher has signal to discriminate on, and consistent enough that the matcher discriminates the same way today as tomorrow. Both conditions are easy to assume and hard to verify. Without an external reference, there is no way to know whether your input text is actually doing the job.
The problem
A learning team was about to wire role-aligned course recommendations into their platform: take each role’s expected capabilities, match against an external course catalogue, surface the best-fit options.
The risk was familiar. A capability sentence that says little, in language that says little, attracts courses that do the same. The matcher does not know whether it is matching on substantive vocabulary or surface terms. It only sees inputs and emits outputs.
So before any matching ran in anger, the text on both sides needed a grading. The corpus we would grade against had to be substantially larger than anything we would reasonably encounter, varied enough across genres and registers that it represented “general English,” and free from internal vocabulary that would skew the baseline. Project Gutenberg fits all three.
The approach
Build a text-complexity benchmark from the corpus, score the capability text against it, audit field by field.
- Corpus. Five thousand books from Project Gutenberg, segmented to paragraph level. Around 32 million sentences after cleanup. Wide spread of genre (fiction, philosophy, history, science) means surface-vocabulary biases largely wash out in aggregate.
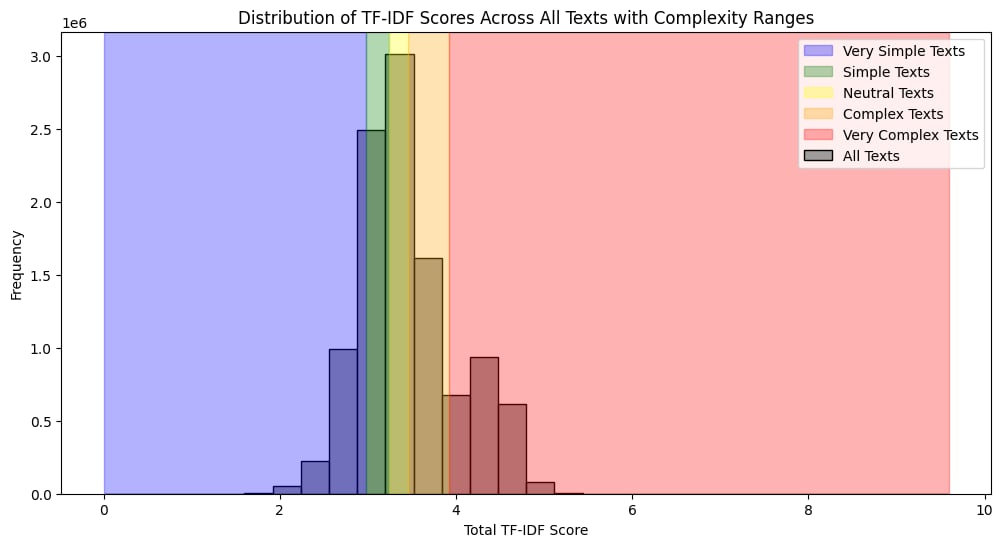
- Complexity score. TF-IDF across the full corpus. Each sentence got a score reflecting how distinctive its vocabulary was compared to general English. Quintiles defined Very Simple through Very Complex bands, with TF-IDF cutoffs at 2.98, 3.24, 3.46, 3.92.
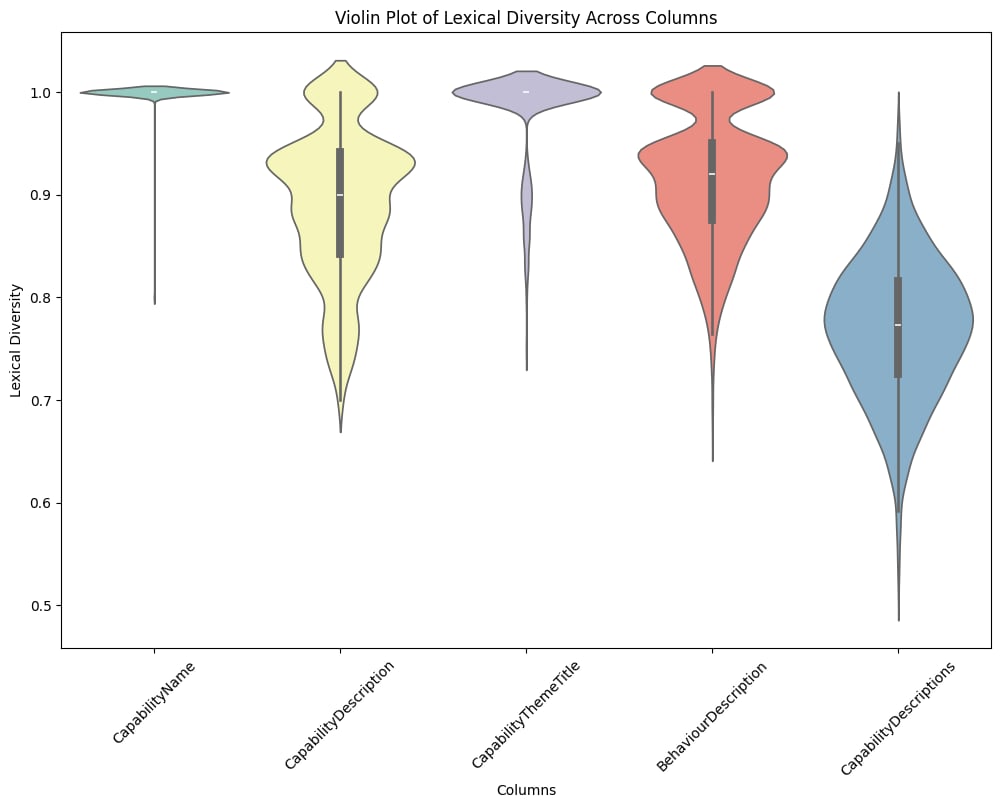
- Linguistic richness. Type-Token Ratio and Lexical Diversity across the corpus. These distinguish “uses long words” from “uses a varied vocabulary.” A field can score high on one and low on the other, and that difference matters when judging whether a matcher has signal to work with.
- Audit. Same scores applied to the capability text, distributions compared field by field: short labels, descriptive copy, theme titles, role-behaviour text.
What the audit found
The fields landed across the complexity spectrum about where you would expect, and that was the point: the predictability validated the benchmark. Short labels skewed Simple. Descriptive copy was broader, with mass in the Neutral and Complex bands. Role-behaviour text spanned every band, because the same field has to describe both junior and senior expectations and the vocabulary scales with seniority.
The more useful finding cut the other way. Individual fields were too sparse on their own to give the matcher signal that was not trivially gameable. Concatenating related fields per capability gave a denser, more varied composite that the matcher could grade against course descriptions of comparable complexity. The team had been treating fields as drop-in alternatives. The audit showed they were not.
Evidence
- 5,000 books, ~32 million sentences scored
- Five complexity bands defined by quintile (TF-IDF cutoffs 2.98, 3.24, 3.46, 3.92)
- Role-behaviour text showed lexical diversity spread across all bands, as designed
- Lowest-value capability descriptions identified and flagged for rewrite before the matcher ran in production
- Composite “field bundle” outperformed any single field as input signal
The benchmark outlived the project that prompted it. Any time text-heavy input arrives at an NLP workflow, the corpus is sitting there, ready to score it.