The fastest way to understand a data-wrangling pipeline is to build the messy dataset yourself, plant the problems you are going to solve, then solve them. This project does exactly that: synthesises a ride-share dataset with realistic shape, drops in the kinds of issues a real dataset would have, and demonstrates a full wrangling pipeline against it. The reusable artefact is the dataset and the cleaning script, not the analytical conclusions.
The problem
Teaching data wrangling against real data has a recurring obstacle: the real data is either too clean (because a tidied copy is what gets shared) or too dirty (because the raw extract has noise unrelated to the lesson). A teachable dataset needs to be calibrated. It has to look like a real-world dataset in distribution and structure, but it also has to have exactly the issues the lesson is about, no more and no less. That calibration is a separate skill from the wrangling itself, and it benefits from being treated as a project in its own right.
The constraint, then: produce two related datasets that join cleanly, contain plausible correlations and category mixes, carry deliberate missing values and outliers, and resist any obvious tell that they are synthetic.
The approach
Generate, merge, understand, manipulate, scan, transform. The same shape as a real wrangling pipeline.
Generate. Two datasets, drivers (50 rows: ID, name, vehicle type, rating, join date) and rides (75 rows: ride ID, driver ID, distance, fare, payment method, date). Distances drawn from a uniform distribution over a plausible urban range. Fares calculated as base rate plus per-kilometre rate plus normal noise, so distance and fare correlate in the way they would in real data. Random missing values planted in three rows of each dataset. Outliers added: one extreme driver rating, one $150 fare, one fifty-kilometre distance.
Merge. Left join on driver ID. The merged dataset preserves every ride and attaches the corresponding driver. The join exposes the rows where a driver-side missing value carries into the merged record, which is a teachable moment in itself.
Understand. Inspect structure, confirm types, convert categorical variables to factors, validate date ranges. The merged dataset has the type-conversion ambiguities a real dataset would.
Manipulate. Derive useful variables. driver_experience_days from the difference between ride date and join date. fare_per_km from the obvious division. estimated_duration_mins from distance and an assumed urban speed. Each derived variable opens new analytical questions.
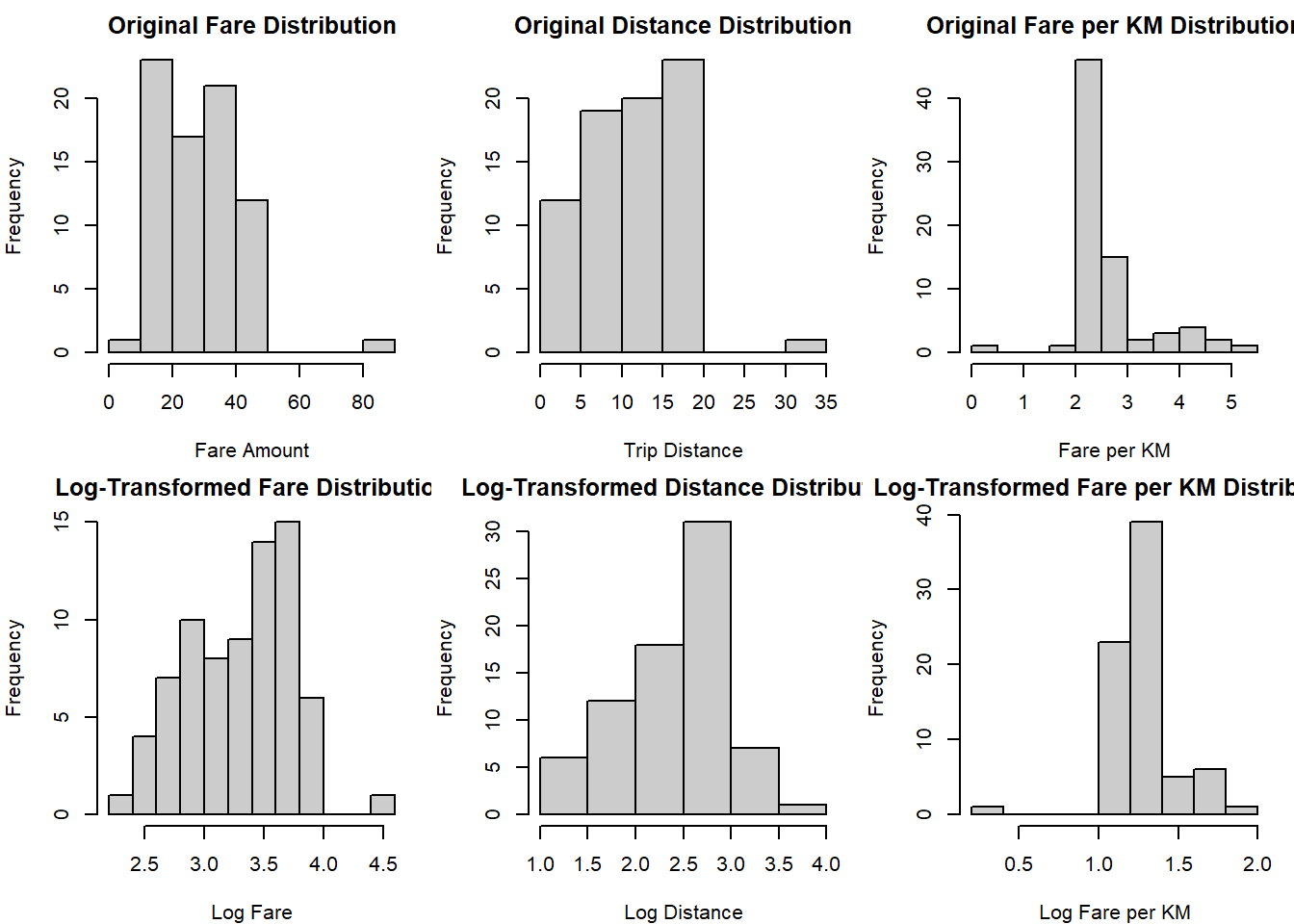
Scan. Missing-value analysis surfaces nine missing driver ratings (12%) and three missing fares (4%). Median imputation handles both, with the choice defensible because median preserves the centre of the distribution under skew.
Transform. Outlier detection by IQR method and z-score, with the results cross-validated. Extreme values capped at three standard deviations. Log transformation (using log(x+1) to handle zeros) on the right-skewed fare and distance variables produces noticeably more symmetric distributions, ready for parametric methods downstream.
What the dataset earns
The point of the exercise is not the dataset’s analytical findings, which are deliberately limited. The point is that the same dataset and the same script will teach the next learner the same lesson, with the same planted issues showing up at the same places in the pipeline. That makes it a reproducible teaching artefact, not a one-time demonstration.
It also makes the generated dataset useful in two adjacent contexts: prototyping wrangling pipelines without touching sensitive data, and benchmarking new wrangling tools against a known-shape input where the answers are already known.
Evidence
- Two related datasets generated (50 drivers, 75 rides), correlated and joinable
- Realistic shape: distance-fare correlation preserved, vehicle-type distribution plausible, payment-method split realistic
- Three deliberate missing values in each dataset, planted to teach NA handling
- Outliers planted at known positions: extreme rating, $150 fare, 50 km distance
- Median imputation, IQR and z-score outlier detection, log transformation all demonstrated
- Final dataset shape: 75 merged rows × 13 columns including derived variables
- Reproducibility guaranteed by
set.seed(3229642)throughout
A small project, useful out of proportion to its size, because every analyst eventually needs to teach (or learn) this pipeline and a calibrated dataset is the friend they did not know they wanted.